









JetBrains today announced that it is open-sourcing Mellum2, a 12B model engineered to solve the hardest parts of production AI: latency, throughput, and cost. Built from scratch and released under the Apache 2.0 license, Mellum2 offers a high-performance, cost-efficient alternative for infrastructure. Mellum began with code completion and has evolved to handle both natural language and code. It is now a versatile tool ready to power routing, summarization, and intermediate reasoning steps across modern AI workflows.
Whether users want to experiment, fine-tune, or deploy at scale, Mellum2 is ready to run in their own systems. Mellum2 is engineered to solve the bottlenecks of production-scale systems through its architecture and focused, efficiency-driven design.
The model features 12B total parameters, but because it uses a Mixture-of-Experts (MoE) design, only 2.5B parameters are active per token. This reduces compute costs while enabling high-throughput, low-latency inference for real-time workloads.
Unlike many modern models, Mellum2 is not multimodal. It is trained specifically on natural language and code data. This specialization ensures the model excels in software engineering environments while remaining lean and fast.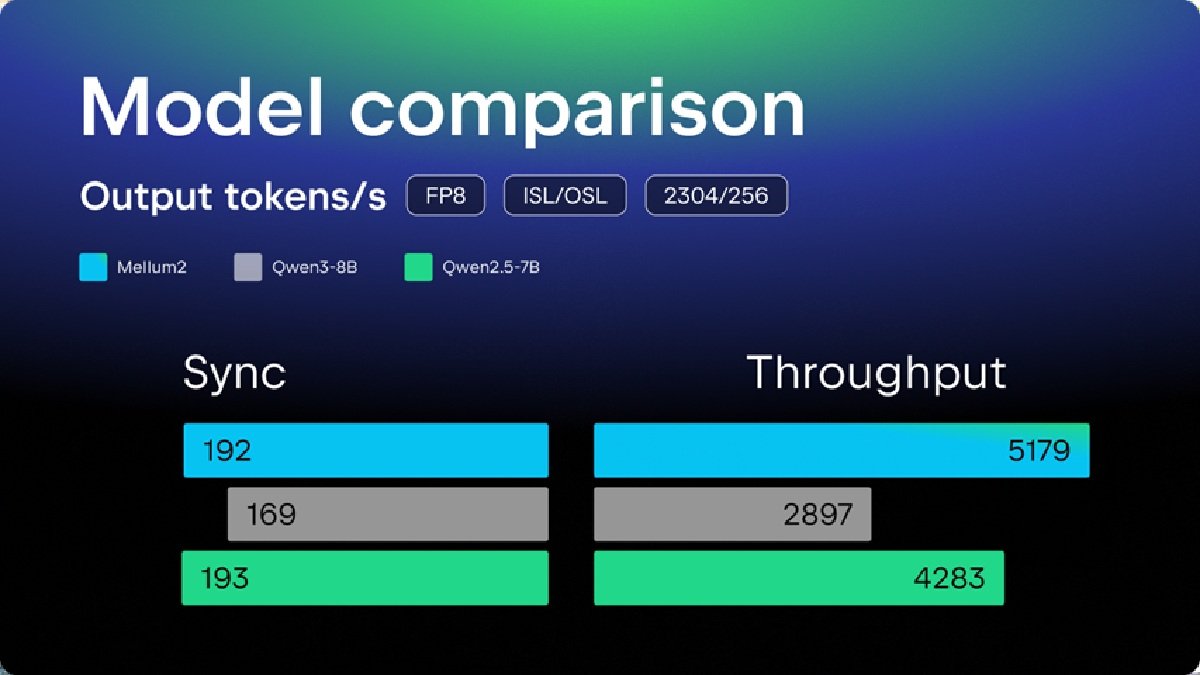 Mellum2 can be used to:
Mellum2 can be used to:
- Route and orchestrate AI workloads: By analyzing incoming prompts and helping select the right model or tool for each task.
- Build low-latency RAG pipelines: By retrieving relevant context, use Mellum2 to summarize it, and generate responses instantly.
- Power fast sub-agents in complex workflows: By supporting agent pipelines into steps like context gathering, planning, and validation.
- Enable private, local AI deployment: By running Mellum2 locally or self-host it to keep code and data fully under your control.
As AI systems become more complex, performance bottlenecks shift from raw capability to latency, throughput, and cost at scale. Not every task requires the largest model. Many steps in modern AI systems are repetitive, latency-sensitive, and high-frequency. These steps benefit from a fast and reliable model that can be efficiently routed, hosted, and controlled.
At JetBrains, the belief is that the future belongs to coordinated systems, not single models. Frontier models will continue to push the limits, but practical AI products also require focal models: fast, specialized components that handle high-frequency tasks efficiently.
JetBrains sees Mellum2 playing this role in the next generation of AI software tooling. Mellum2 is available as an open-source model under the Apache 2.0 license.
